불균형 데이터 분류
이진 분류 문제를 푸는데 테스트 케이스들이 전부 너무 낮은 확률이 나온다.

Google Brain team에서 개발한 머신러닝 프레임워크. Python Friendly하게 만들어져 일반인들도 사용하기 쉬운(?)편이다. 아직까지는 다른 프레임워크들과 대비해 커뮤니티가 활발하고 자료가 많아 간단하게 개발하는데 있어서 유용하다.
Facebook’s AI Research lab에서 개발한 PyTorch와 가장 큰 차이점은 고정된 신경망이냐 레이어 구조의 신경망이냐의 차이인데, 레이어 구조를 사용하는 PyTorch가 더 최적의 학습효과를 보여준다. 하지만, 큰 프로젝트나 복잡한 workflow에서는 TensorFlow가 더 뛰어난 퍼포먼스를 보여준다고 한다.
또 다른 머신러닝 프레임워크들로는 neural network에 특화된 마이크로소프트의 CNTK, 그리고 Amazon의 Apache MXNet 등이 있다.
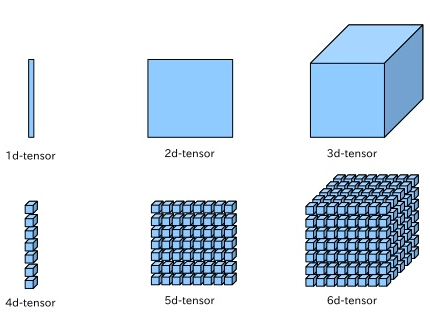
Machine Learning에서 Data가 Neural Network를 타고 들어갈때의 단위라고 보면 된다. 배열이나 행렬 정도로 느낌을 가져가면 ‘우선’은 이해가 편하다. 결국 Machine Learning이란게 Data들에 가중치를 부여하면서 선형결합을 하여 다음 노드(node)를 만들고 또 다음 층(layer)으로 선형결합을 하며 이루어지는데 이게 결국 tensor의 연산이다.
너무 수학적 혹은 물리적으로 갈 것 까지는 없고, 1차원 벡터, 2차원 매트릭스 3차원 부터 텐서라고 한다고 생각하면 편하다.
TensorFlow 사이트에 잘 정리된 튜토리얼이 있습니다. 같은 구글이라서 전에 Youtube API 문서 들여다 봤던 거랑 느낌이 아주 유사하네요.
차근차근 포스팅 할 예정입니다.
이진 분류 문제를 푸는데 테스트 케이스들이 전부 너무 낮은 확률이 나온다.
분류 문제에서 손실 함수와 마지막 레이어의 활성 함수 선택 Tip.
Optimizer?
Beginner에서 사용한 MNIST 숫자 손글씨 보다 조금 더 어려운 Fashion dataset으로 실습해보자.
가장 기본 튜토리얼. 아직 머신러닝 공부가 부족하여 손실 함수 등 이해가 필요한 부분이 많다. 그래도 무언가 훈련하고, 답을 찾아내는게 보여서 신기하다.
험난했던 TensorFlow 설치 여정