
TensorFlow Tutorial (3) - Fahsion MNIST
Beginner에서 사용한 MNIST 숫자 손글씨 보다 조금 더 어려운 Fashion dataset으로 실습해보자.
Data Load
사용할 데이터는 Fashion MNIST. 손글씨 MNIST 이미지 dataset 구조와 동일하며 이번에는 의류 이미지가 저장되어 있다. 불러오는 방법은 이전과 같은니 상세 설명은 생략. 이번에는 숫자 0~9 대신 라벨링을 위해 따로 class_names를 지정해 준다.
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
Explore data
이전 튜토리얼 보다 조금 심화된 image 출력 방법이다. TensorFlow와는 크게 관계 없고 pyplot 사용법이라 상세설명은 생략. (MATLAB과 거의 비슷한 느낌으로 출력하는거라 크게 어렵진 않음)
- 출력값
# single image
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
# to 0 ~ 1 float value
train_images = train_images / 255.0
test_images = test_images / 255.0
# display images
plt.figure(figsize=(10, 10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()

Model
Build and Compile
마찬가지로 이전에서 하는 방법은 똑같고, layer 구성 설명과 compile 세팅에 대해서 조금 더 알아보자.
## Build the Model
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
네트워크의 첫번째 레이어인 tf.keras.layers.Flatten은 2차원 배열의 이미지를 1차원 배열로 변환해 준다. 그렇게 픽셀을 펼친 후에는 tf.keras.layers.Dense 층이 연속되어 연결되는데, 이 층을 밀집 연결(densely-connected) 또는 완전 연결(fully-connected)이라고 부른다.
첫번째 Dense층은 128개의 노드(뉴런)을 가진다는 의미이고, 두번째 층은 크기가 10인 logits 배열을 반환하게 된다.
## Compile the Model
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
- 손실 함수(Loss function) : 훈련 하는 동안 모델의 오차를 측정. 모델의 학습이 올바른 방향으로 향하도록(steer) 이 함수를 최소화해야 한다.
- 옵티마이저(Optimizer)-데이터와 손실 함수를 바탕으로 모델의 업데이트 방법을 결정.
- 지표(Metrics)-훈련 단계와 테스트 단계를 모니터링하기 위해 사용.
Train & Evaluate
model.fit(train_images, train_labels)으로 훈련시키고 model.evaluate(test_images, test_labels)로 검증한다.
## Train the Model
model.fit(train_images, train_labels, epochs=10)
## Evaluate accuracy
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc) # evaluate는 loss와 accuracy를 return 한다.
Predictions
Make Predictions
Model의 linear ouput인 logits을 probability로 전환하는 과정이라고 볼 수 있다.
softmax layer을 trained model에 붙여 probability_model을 만든다. batch 단위로 prediction을 만들게 되는데, 0번 인덱스 값을 보면 각 라벨에 대한 가능성 값(0~1)이 array로 저장되어 있음을 알 수 있다. 이 가능성이 가장 높은 값으로 model은 test_image의 test_label 값이라고 판단을 내리게 되는 것이다.
probability_model = tf.keras.Sequential([model, tf.keras.layers.Softmax()])
predictions = probability_model.predict(test_images)
print(predictions[0]) # 각 라벨 array에 대한 가능성(0~1)값이 저장되어 있음.
np.argmax(predictions[0]) # array에서 가장 max인 값을 갖는 idx = 가장 확률이 높은 라벨
- 출력값
Test accuracy: 0.8831999897956848
[1.4358394e-06 2.6443854e-06 1.5080674e-07 7.2667844e-11 9.3509050e-07
1.0772155e-03 5.2454016e-07 1.6904406e-02 1.5072420e-07 9.8201263e-01]
위 출력값을 해석하자면 test 결과 정확도는 88% 정도 이고, 0번 test 이미지는 가능성이 9.8e-01로 가장 큰 9번 ‘Ankle Boots’로 추정할 것이라는 걸 알 수 있다.
Verify Predictions
아래 이미지 출력 방법 또한 pyplot 활용이므로 Python Script로 대체한다.
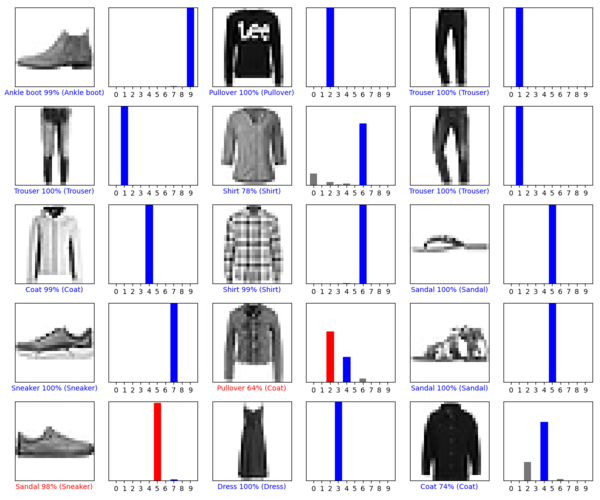
red는 prediction한 결과 값(label), blue는 실제 값이다. 그림과 같이 모델은 확률적으로 가장 높은 값으로 라벨을 추정한다. red로 표시된 test는 실제 라벨과 추정 라벨이 일치 하지 않았음을 알 수 있다. (확률이 88%니 15개 중에 1~2개 틀릴 수 있는 것)
Use the trained model
특정 이미지의 추정 결과를 알고 싶다면 batch 형태로 입력 해주는 것만 주의하면 된다.
img = test_images[1]
img = (np.expand_dims(img,0)) # keras는 batch 형태의 셋을 다루는데 최적화 되어 있으므로, dimseion을 늘려줘야한다. (28X28) -> (1x28x28)
predictions_single = probability_model.predict(img) # 훈련된 probability model로 predict한다.