
TensorFlow Tutorial (4) - Optimizer
Optimizer?
keras에서 model을 compile할 때 입력하는 변수 중에 ‘optimizer’라는 것이 있습니다. 아래 코드에서와 같이 ‘adam’이라는 이름의 optimizer를 넣는 모습을 볼 수 있는데요, 이 optimizer가 무엇을 최적화 하느냐? 바로 learning rate입니다.
## Compile the Model
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
learning rate의 개념을 이해하기 위해서는 기본적인 머신러닝의 원리를 알아야 합니다. 머신러닝은 결국 설정한 Neural Network에서 예측과 실제값의 오차 혹은 손실(loss)이 최소가 되는 가중치를 찾는 일이라고 할 수 있습니다. 이 때, 손실이 최소가 되는 가중치를 찾는 과정에서 모든 값들을 테스트해 볼 수도 있겠지만, 어느 정도의 값은 스킵하고 다음 값을 테스트 해 보는 것이 불필요한 시간 낭비를 줄일 수 있을 것입니다.
여기서 ‘얼마나’ 스킵 할 것인가가 바로 learning rate 개념 입니다.
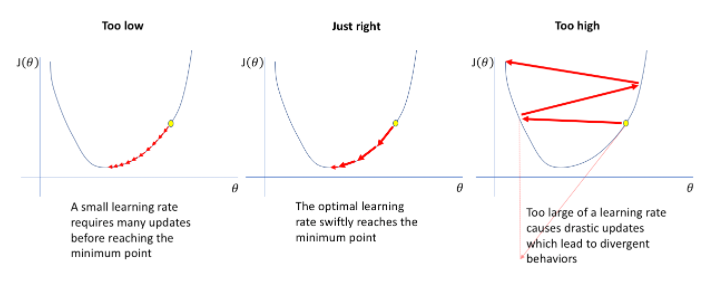
위 그림과 같이 learning rate를 작게(Too low) 가져가면 하나하나 다 체크를 하기 때문에 loss 최소값에 도달 할 수는 있겠지만 엄청난 시간이 걸릴 겁니다. 반대로 너무 큰(Too high) 값을 가져가게 되면 최소값이 될 수도 있는 구간을 뛰어 넘어 버려 원하는 결과를 얻지 못할 것입니다.
그래서 학습이 일어나는 동안 어떤 로직을 가지고 이 learning rate를 조절해 줄 필요가 있습니다. 그 로직이 이 optimizer가 한다고 보면 됩니다.
Gradient descent optimization algorithms
learning rate를 optimization하는 알고리즘 중에서 가장 대표적인 방법이 Gradient Descent Optimization Algorithms(경사하강법) 입니다. 그 외에도 다른 알고리즘이 있겠지만 이 경사하강법이 제일 많이 쓰이고 정론으로 알려져 있습니다.
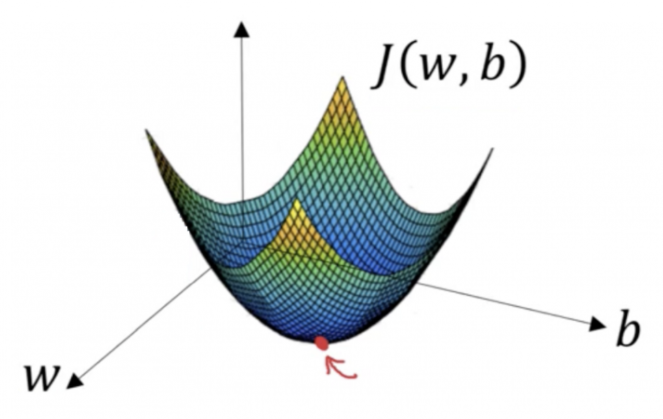
경사하강법은 Cost Function J(w,b)의 최소값을 찾을 때 경사가 큰 쪽으로 다음 탐색 포인트를 찾습니다. 아래 그림에서 가장 깊은 곳인 빨간 점을 찾아나가는 겁니다.
이 때 다양한 방법들이 존재하는데 흔히 사용하는 ‘adam’도 그 경사하강법의 기법 중 하나 입니다.
저도 아직 배우는 단계라 깊게는 들어가지 못하고, 어떤 종류가 있는지만 짧게 살펴보겠습니다.
링크의 포스트를 참조했습니다.
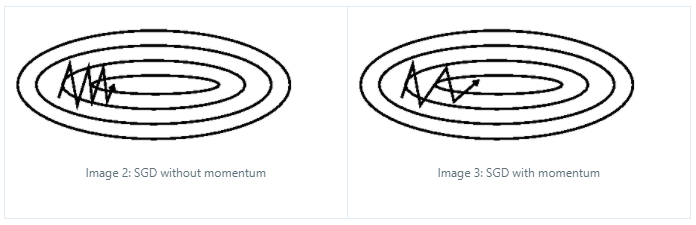
1. Momentum
언덕에서 공을 굴리는 것과 같이, 오른 쪽 그림 처럼 경사가 있다면 그 관성을 고려하여 learning rate를 크게 잡아줍니다.
2. Adagrad
learning rate를 설정 할 때, 파라미터의 변화가 작으면 빠르게, 파라미터의 변화가 크면 느리게 조절준다.
$theta_i$ \theta_i \theta_i\
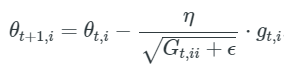
에타(learning rate)의 분모에 Gt가 그래디언트들의 합이기 때문에, 변화가 큰 경우 다음 파라미터를 탐색 할 때 작은 learning rate로 탐색하고 또한 역으로 작으면 큰 learning rate로 탐색 하는 것을 알 수 있다.
3. Adadelta
Adagrad에서 Gt가 모든 과거 그래디언트들의 제곱을 더하는게 아니라, 특정 window를 둬서 제한한 알고리즘입니다. learning rate가 너무 작아져서 학습이 멈추는 것을 방지한다고 합니다.
4. RMSprop
RMS이름에서도 유추(?) 할 수 있듯이 Adagrad의 Gt항을 그래디언트의 제곱함으로 처리하게 됩니다.
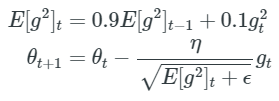
5. Adam
RMSporp와 Adadelta를 합친 방법이라고 보면 됩니다. 예시로 가장 많이 쓰이는 것으로 보니, Performance가 가장 좋은 것 같습니다.
Cost, Activation, Loss Function
Cost Function과 Loss Function은 혼용해서 쓰이는데, 정확히 구분하자면 전체 모델에 대한 loss는 Cost Function, 하나의 training set에 대한 loss error는 Loss Function으로 나타낸다고 보면 될 것 같습니다.
Cost function (J) = 1/m (Sum of Loss error for ‘m’ examples)
Activation Function은 data를 찌그러트려서 원하는 모양으로 만든다고 볼 수 있습니다. 예를 들어, 0 혹은 1로만 데이터를 받고 싶은데 0.3, 0.7 이런 값들을 activation Function으로 왜곡시켜 0 또는 1로 만들어 주는 겁니다. 혹은 음수가 나올 경우 강제로 0으로 만들어 줄 수도 있습니다. (“ReLU” or “Rectified Linear Unit”)
자세한 내용은 기회가 되면 다뤄 보겠습니다. 우선은 다음을 참고하세요.